利用Selenium自动化工具高效爬取购物网站商品数据实践指南
一、Selenium在数据爬取中的应用优势
Selenium是一个强大的Web自动化测试工具,但在数据爬取领域同样展现出独特的价值。与传统requests+BeautifulSoup组合相比,Selenium能够模拟真实用户操作,完美应对JavaScript动态加载的网页。对于购物网站这类大量使用AJAX技术、需要用户交互才能显示完整数据的平台,Selenium提供了无可替代的解决方案。
二、环境配置与基础准备
2.1 必要工具安装
首先需要安装Python环境,建议使用3.7及以上版本。通过pip安装Selenium库:`bash
pip install selenium`
2.2 浏览器驱动配置
根据使用的浏览器下载对应驱动:
- Chrome浏览器:ChromeDriver
- Firefox浏览器:GeckoDriver
- Edge浏览器:Microsoft Edge Driver
将驱动文件放置在系统PATH路径或项目目录中,确保Selenium能够调用。
三、实战:以购物网站为例的数据爬取
3.1 基础爬取框架
`python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
初始化浏览器驱动
driver = webdriver.Chrome() # 或使用其他浏览器驱动
访问目标网站
targeturl = "https://www.example-mall.com" # 替换为实际购物网站网址
driver.get(targeturl)
等待页面加载
wait = WebDriverWait(driver, 10)`
3.2 商品数据定位与提取
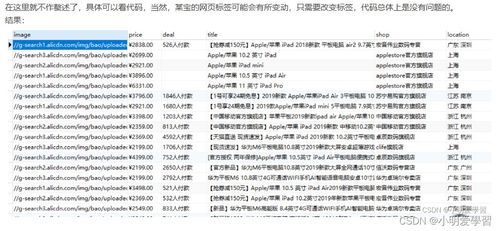
购物网站商品数据通常包含以下关键信息:
- 商品名称:通过class、id或XPath定位
- 价格信息:注意原价、促销价等不同价格元素
- 商品评分:星级评价或分数
- 评论数量:用户评价总数
- 商品图片:获取图片URL
- 商品链接:详情页地址
`python
# 示例:提取商品列表
def extractproductdata(driver):
products = driver.findelements(By.CLASSNAME, "product-item") # 根据实际网站结构调整
productlist = []
for product in products:
try:
name = product.findelement(By.CLASSNAME, "product-name").text
price = product.findelement(By.CLASSNAME, "product-price").text
# 更多数据提取...
productlist.append({
"name": name,
"price": price,
# 其他字段...
})
except Exception as e:
print(f"提取商品数据时出错: {e}")
continue
return product_list`
3.3 处理分页与动态加载
购物网站通常采用分页或无限滚动加载:`python
# 分页处理
pagenum = 1
maxpages = 5 # 设置最大爬取页数
all_products = []
while pagenum <= maxpages:
# 提取当前页数据
currentproducts = extractproductdata(driver)
allproducts.extend(current_products)
# 查找并点击下一页按钮
try:
nextbutton = driver.findelement(By.CSSSELECTOR, ".next-page")
nextbutton.click()
time.sleep(2) # 等待页面加载
page_num += 1
except:
print("已到达最后一页或找不到下一页按钮")
break`
3.4 数据存储
`python
import pandas as pd
import json
保存为CSV
pd.DataFrame(allproducts).tocsv("shopping_data.csv", index=False, encoding="utf-8-sig")
保存为JSON
with open("shoppingdata.json", "w", encoding="utf-8") as f:
json.dump(allproducts, f, ensure_ascii=False, indent=2)`
四、高级技巧与优化策略
4.1 反爬虫规避
1. 设置请求间隔:避免过快请求
`python
import random
time.sleep(random.uniform(1, 3)) # 随机等待1-3秒
`
2. 使用代理IP:
`python
from selenium.webdriver.chrome.options import Options
chromeoptions = Options()
chromeoptions.addargument('--proxy-server=http://your-proxy-ip:port')
driver = webdriver.Chrome(options=chromeoptions)
`
- 模拟人类操作:添加鼠标移动、滚动等操作
4.2 性能优化
1. 无头模式:不显示浏览器界面,减少资源消耗
`python
chromeoptions.addargument('--headless')
`
2. 禁用图片加载:加快页面加载速度
`python
chromeoptions.addargument('--blink-settings=imagesEnabled=false')
`
4.3 异常处理与稳定性
try:
element = WebDriverWait(driver, 10).until(
EC.presenceofelement_located((By.ID, "target-element"))
)
except TimeoutException:
print("元素加载超时")
driver.savescreenshot("errorscreenshot.png") # 保存错误截图
finally:
driver.quit() # 确保浏览器关闭五、伦理与法律注意事项
- 遵守robots.txt:检查目标网站的爬虫政策
- 控制请求频率:避免对目标网站造成过大压力
- 仅用于合法用途:遵守相关法律法规和网站服务条款
- 尊重数据版权:合理使用爬取的数据
六、完整示例代码框架
`python
import time
import random
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
class ShoppingSiteCrawler:
def init(self, baseurl):
self.baseurl = baseurl
self.driver = self.setupdriver()
def setupdriver(self):
options = webdriver.ChromeOptions()
# options.addargument('--headless') # 可选:无头模式
driver = webdriver.Chrome(options=options)
driver.implicitlywait(5)
return driver
def crawlproducts(self, maxpages=10):
self.driver.get(self.baseurl)
allproducts = []
for page in range(1, maxpages + 1):
print(f"正在爬取第 {page} 页...")
# 提取数据
products = self.extractcurrentpage()
all_products.extend(products)
# 翻页
if not self.gotonext_page():
break
# 随机延迟
time.sleep(random.uniform(2, 4))
return allproducts
def extractcurrent_page(self):
# 实现具体的数据提取逻辑
pass
def gotonext_page(self):
# 实现翻页逻辑
pass
def savedata(self, data, filename):
pd.DataFrame(data).tocsv(filename, index=False, encoding="utf-8-sig")
print(f"数据已保存至 {filename}")
def close(self):
self.driver.quit()
使用示例
if name == "main":
crawler = ShoppingSiteCrawler("https://www.example-shopping-site.com")
try:
productdata = crawler.crawlproducts(maxpages=5)
crawler.savedata(productdata, "shoppingproducts.csv")
finally:
crawler.close()`
通过以上方法,您可以高效、稳定地爬取购物网站的商品数据。请根据具体网站结构调整定位策略,并始终遵守网络爬虫的道德规范和法律要求。
如若转载,请注明出处:http://www.kk15.com/product/313.html
更新时间:2026-02-10 04:22:49